Status Quo & Trends bei der automatischen Spracherkennung

Inhaltsverzeichnis dieses Artikels
- Was ist Spracherkennung?
- Wissenschaftliche Studie: Trefferquote von automatischer Spracherkennung bei 67,6%
- Anwendungsfelder der automatischen Spracherkennung
- Geschichte der automatischen Spracherkennung
- Funktionsweise von Speech-to-Text Systemen
- Chancen und Herausforderungen der automatischen Spracherkennung
- Wichtigste Anbieter für automatische Spracherkennung
Dieser Artikel ist ein Ausschnitt aus unserem eBook Aufnehmen, Abtippen, Analysieren – Wegweiser zur Durchführung von Interview & Transkription.
Das Buch gibt es als kostenloser Download: Jetzt alles zu Transkription & Co erfahren!
Was ist Spracherkennung?

Obwohl Maschinen heute auch schon über einzelne der Fähigkeiten von HAL – wie zum Beispiel das Schachspiel oder die Navigation eines Raumschiffs – verfügen, sind wir von einer intelligenten, sinnvollen und bidirektionalen Kommunikation zwischen Mensch und Maschine noch , immer weit entfernt.
Mit Spracherkennungssoftware sind spezielle Computerprogramme oder Apps gemeint, die gesprochene Sprache erkennen und automatisch in schriftlichen Text umwandeln. Die Sprache wird dabei in Bezug auf gesprochene Wörter, Bedeutung und Sprechercharakteristiken analysiert, um ein möglichst genaues Ergebnis zu erzielen. Dies ist nicht zu verwechseln mit der Stimmerkennung, also einem biometrischen Verfahren, um Personen anhand ihrer Stimme zu identifizieren.
Mit Hilfe von Spracherkennungssoftware wird gesprochene Sprache automatisch in Text umgewandelt – dabei kann zwischen sprecherabhängiger und sprecherunabhängiger Spracherkennung unterschieden werden
Mittlerweile lässt sich mithilfe von Spracherkennung der PC steuern, man kann durch sie E-Mails schreiben oder im Internet surfen. Zahlreiche Lautsprecher mit integrierter Sprachsteuerung, wie z.B. Alexa von Amazon oder Google Home nutzen diese Technik ebenfalls. Darüber hinaus ist sie mittlerweile serienmäßig in den meisten Smartphones enthalten.
- Sprecherunabhängige Spracherkennung: Hierbei kann jede beliebige Stimme erkannt und verarbeitet werden und eine Bedienung des Gerätes ist somit für jeden möglich. Zwar richtet sich diese Art der Anwendung an eine breite Zielgruppe, allerdings ist der vorhandene Wortschatz hier begrenzt.
- Sprecherabhängige Spracherkennung: Bei dieser Variante wir das Programm auf die individuelle Sprache des jeweiligen Nutzers trainiert, wodurch spezifische Abkürzungen und Wendungen erlernt werden können. Der Wortschatz ist dadurch wesentlich umfangreicher.
Vom technischen Standpunkt aus, gibt es zwei mögliche Wege der Abwicklung dieses Prozesses. Entweder, er findet auf dem jeweiligen Gerät des Nutzers direkt statt, wodurch das Ergebnis nahezu unmittelbar vorliegt (Front-End), oder die Umsetzung erfolgt auf einem gesonderten Server, unabhängig vom Gerät des Nutzers (Back-End).
Eine große Rolle spielt bei diesem Prozess natürlich die Qualität der Tonaufnahme. Viele Sprecher, Störgeräusche oder eine zu hohe Entfernung zum Mikrofon beeinflussen das Ergebnis negativ. Aufgrund dieser Einschränkungen und weiterer Schwierigkeiten, wie z.B. individuelles Sprecherverhalten oder Dialekt, ist eine komplett automatisierte Transkription (noch) nicht fehlerfrei möglich und sie ist somit der menschlichen manuellen Transkription qualitativ unterlegen. In jedem Fall ist deshalb eine menschliche Nachkorrektur erforderlich, wenn ein gewisses Qualitätsniveau erreicht werden soll. Unter optimalen Bedingungen und bei vorherigem Training anhand der Stimme des Nutzers sind die Ergebnisse jedoch bereits gut. Insbesondere unter Berufsgruppen wie Ärzten oder Juristen gibt es schon zahlreiche Anwender.
Für die automatische Spracherkennung ist die Qualität der Aufnahme besonders wichtig – Herausforderungen stellen viele Sprecher, Störgeräusche sowie Abweichungen von der Standardaussprache dar. Generell ist eine menschliche Nachkorrektur erforderlich.
mp3, .aif, .aiff, .wav, .mp4, .m4a und .m4v
Marktführer auf diesem Gebiet ist Dragon – Dragon Professional 15 bietet umfangreiche Funktionen für die Transkription
Das Programm kann keine Sprecherzuordnung vornehmen und sollte für ein gutes Ergebnis auf die eigene Stimme trainiert werden
Mittlerweile haben auch andere große Konzerne wie Google diesen Markt für sich entdeckt und bieten neben den sprachgesteuerten Lautsprecher auch Lösungen für automatisierte Transkriptionen an. Mithilfe von Google Cloud Speech API kann ebenfalls Sprache in Text umgewandelt werden. Dabei werden zusätzlich neuronale Netzwerke und maschinelles Lernen eingesetzt, um die Ergebnisse stetig zu verbessern.
Eine Alternative bietet Google Cloud Speech – hier befindet sich die Sprecherzuordnung in der Testphase
Ohne vorab trainierte Sprachmuster ist der Korrekturaufwand meist sehr hoch – Eine Sprecherzuordnung muss noch manuell vorgenommen werden
Wissenschaftliche Studie: Spracherkennung liegt bei 67,6% Genauigkeit
abtipper.de hat im 2019 und 2020 eine wissenschaftliche Studie unternommen, um die Leistungsfähigkeit der aktuell sieben für den deutschen Sprachraum verfügbaren Spracherkennungssysteme zu beurteilen. Neben großen Anbietern wie Google und Alexa wurden dabei auch eine Reihe von kleineren Nischenanbietern untersucht.
Im Test wurde geprüft, wie hoch die Worterkennungsrate bei einer normalen Gesprächsaufnahme mit zwei Personen ist, also einer typischen Interviewsituation. Ein Mensch erreicht hierbei abhängig vom Themengebiet und seiner Erfahrung bei einer manuellen Audiotranskription eine Quote von 96-99%. Das heißt, dass bei 100 Wörtern üblicherweise 1-4 Fehler in der menschlichen Transkription auftreten.
Das beste Spracherkennungssystem erreichte einen Wert von 67,6%. Es werden also aktuell 2/3 der Wörter korrekt erkannt. Selbst einige der größeren Systeme liegen aktuell allerdings noch weit unter diesem Wert, am schlechtesten schnitt das System von Bing ab.
Übersicht zur Qualität (in Prozent) maschinell erstellter Transkripte, als Ergebnisse einer wissenschaftlichen Studie:
Qualität erstellter Transkripte
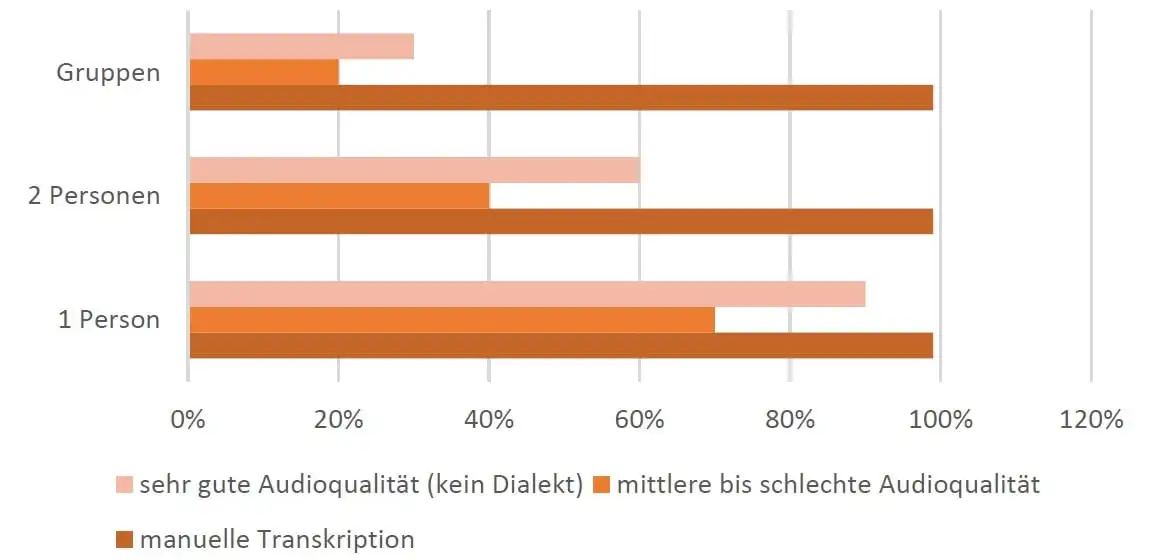
Alles in allem erreicht aber die maschinelle Transkription i.d.R. noch nicht das Niveau einer manuell erstellten Transkription. Für einen ersten Eindruck folgt hier ein Beispiel für die Transkription eines Interviews (mit zwei Sprecherinnen) mit künstlicher Intelligenz. Dieses wurde von einem der zurzeit bekanntesten Transkriptionsprogramme, Google Cloud Speech-to-Text, erstellt.
Beispielhaftes Ergebnis einer Sparcherkennung:
Interview Anette Bronder auf der Hannover Messe
(Ausschnitt aus: https://www.youtube.com/watch?v=Es-CIO9dEwA, zugegriffen am 08.05.2019)
„die Digitalisierung und Vernetzung spielt auch in diesem Jahr auf der Hannover Messe Industrie eine bedeutende Rolle die Telekom ist zum dritten Mal mit einem Stand vertreten und zeigt ganz konkrete Anwendungsbeispiele das Motto lautet Digitalisierung einfach machen Frau Bronder was verstehen sie eigentlich darunter einfach machen können wir uns ein Beispiel geben ja sehr mir schon gutes Stichwort geliefert einfach machen sie sagten ja gerade eben die Messe wird zum dritten Mal zum Thema aufdigitalisierung hier auf der Hannover-Messe ich glaube jetzt ist der Zeitpunkt gekommen von Mama aus dem Labor rein in die Praxis muss das erwarten konnten jetzt ist er wartet auch der Standort Deutschland nehme ich mit Lösungen zu kommen explizit auch für Mittelstand aber auch für große Kunden die anwendbar sind die standardisiert sind er mir zum ersten Starter-Kit eine Box mit der Hardware mit Sensorik wo wir das Thema Daten sammeln dass Daten auswerten schon Kundin sehr einfach machen welche weiteren Technologien und Lösungen stellt die Telekomkommt noch hier vor jede Menge ich möchte aber darauf hinweisen dass es uns wichtig ist dieses Jahr zu sagen wäre nicht Technologie und Lösungen das sind wir Status haben wir aber wir bieten das Thema Internet der Dinge als Servicepaket an zum allerersten Mal wir sind in der Lage connectivity über unser gutes Netz zu liefern Cloud-Lösungen Security- Lösungen bis hin zu einzelnen Detaillösungen in der Analytics“
Hier ist noch einmal zu erkennen, dass von der „KI“ keine Sprecherzuordnung vorgenommen wird. Auch die Zeichensetzung wird hier nicht berücksichtigt.
Insgesamt kann man festhalten, dass sich die automatisierte Spracherkennung aktuell für zwei Anwendungsfelder eignet:
- Bei Diktaten (z.B. von Anwälten oder Ärzten): Bei diesen Aufnahmen mit meist nur einem immer gleichen Sprecher und einer hervorragenden Audioqualität, zudem einem eingegrenzten Vokabular kann ein Tool sehr gut auf die entsprechende Stimme und das Vokabular trainiert werden und so gute Ergebnisse liefern.
- Bei niedrigen Anforderungen an die Transkriptionsqualität kann der Einsatz ebenfalls sinnvoll sein. Dies ist z.B. bei der Digitalisierung von Hörfunkarchiven der Fall, bei denen die Durchsuchbarkeit das Ziel ist und daher keine perfekten Transkripte nötig sind. Bei einer oft extrem großen Menge an Material ist bei solchen Anwendungen eine manuelle Transkription aus Wirtschaftlichkeitsgründen von vornherein ausgeschlossen.
Für alle weiteren Zwecke, z.B. Interviews, eignet sich die automatisierte Spracherkennung auf dem aktuellen technischen Stand leider noch nicht. Hier sind möglicherweise in den kommenden Jahren und Jahrzehnten aber weitere Entwicklungen zu erwarten.
Das Ergebnis zeigt, dass vor allem bei Situationen mit mehreren Sprechern die Systeme der automatisierten Spracherkennung noch sehr zu wünschen übrig lassen. Für die Transkription sind sie nur für ganz spezifische Anwendungsfälle (z.B. Digitalisierung von Archiven, die sich sonst finanziell nicht lohnen würden). Anders sieht es hingegen bei Aufnahmen mit nur einem Sprecher aus (z.B. das typische Diktat). Hier erreichen die Systeme aktuell schon Werte um 85% und lassen sich so bereits für einige Praxisanwendungen sinnvoll einsetzen.
Für die Erkennung von vorher bekannten Befehlen (z.B. Alexa Skills) gibt es bereits einige vergleichbare Erhebungen. Diese spiegeln aber eine unnatürliche Sprechsituation mit vorher bekannten Themen und Befehlen wider. Die Qualität einer freien Spracherkennung ohne künstlich eingegrenzten Wortschatz wurde nun durch abtipper.de erstmalig wissenschaftlich für den deutschen Sprachraum untersucht.
Anwendungsfelder der automatisierten Spracherkennung
Schon heute gibt es zahlreiche praktische Einsatzgebiete für Audio-Transkriptionen. Neben dem exponentiellen Nutzungsanstieg der Smartphone-Spracherkennung, etwa zum schnellen Verfassen von Kurznachrichten und Emails oder zur Steuerung von Sprachassistenzsystemen wie Apple‘s Siri, Amazon‘s Alexa oder Microsoft‘s Bing, sind Sprachtranskriptions-Technologien auch aus Call Centern und Krankenhäusern heute nicht mehr wegzudenken.
Tatsächlich ist es uns bei abtipper.de gelungen, seit 2018 als erster Anbieter in Deutschland Transkriptionen durch künstliche Intelligenz anzubieten:

Schon heute gibt es zahlreiche praktische Einsatzgebiete für Audio-Transkriptionen. Neben dem exponentiellen Nutzungsanstieg der Smartphone-Spracherkennung, etwa zum schnellen Verfassen von Kurznachrichten und Emails oder zur Steuerung von Sprachassistenzsystemen wie Apple‘s Siri, Amazon‘s Alexa oder Microsoft‘s Bing, sind Sprachtranskriptions-Technologien auch aus Call Centern und Krankenhäusern heute nicht mehr wegzudenken.
Tatsächlich ist es uns bei abtipper.de gelungen, seit 2018 als erster Anbieter in Deutschland Transkriptionen durch künstliche Intelligenz anzubieten:
Auch wenn die Qualität der Transkription durch künstliche Intelligenz noch nicht ganz an die der manuellen Transkription heranreicht, gibt es viele Anwendungsfelder, für die sich diese besonders eignet. Dies gilt vor allem bei der Digitalisierung von großen Datenmengen, bei denen eine manuelle Transkription sich preislich nicht lohnen wäre.
Klicken Sie hier für ein Beispiel von einem durch künstliche Intelligenz erstellten Transkript.
Vorgehensweise bei der Transkription mit künstlicher Intelligenz: Akzeptable Resultate lassen sich bei diesem Transkriptionstyp nur dann erzielen, wenn die oben genannten Kriterien erfüllt sind. Daher prüfen wir alle entsprechenden Einlieferungen erst einmal durch unsere Experten. Sollte sich z.B. aufgrund von Dialekt, Störgeräuschen oder zu vielen Sprechern kein gutes Transkript erstellen lassen, dann erhalten Sie dies inklusive der detaillierten Begründung innerhalb von 6 bis maximal 24 Stunden mitgeteilt. Ihnen steht es dann frei, einen anderen Transkriptionstyp zu wählen.
Wir bieten Ihnen bei diesem Transkriptionstyp an, dass wir kostenlos und unverbindlich zwei Minuten Ihrer Datei als Probetranskript erstellen, so dass Sie das Ergebnis dieser neuen Transkriptionsart prüfen können. Sie können dann für den konkreten Fall entscheiden, ob die Qualität Ihren Ansprüchen genügt oder ob sich doch eine manuelle Transkription anbietet. Lösen Sie dafür bitte eine Bestellung aus und vermerken Sie im Kommentarfeld, dass Sie die kostenlose Probetranskription wünschen.
Die Geschichte der automatischen Spracherkennung – ein Rückblick

Die Anfänge der Forschung an Spracherkennungssystemen begann bereits früh in den 1960er Jahren, jedoch lieferte sie keine vielversprechenden Ergebnisse. Erste durch IBM entwickelte Systeme ermöglichten eine Erkennung von Einzelwörtern unter Laborbedingungen, lieferten aber aufgrund mangelnden technischen Wissens auf dem neuen Forschungsgebiet zu der damaligen Zeit keine signifikanten Fortschritte – das ging auch aus einem Bericht hervor, den der US-amerikanische Ingenieur John Pierce, Experte auf dem Gebiet der Hochfrequenztechnik, Telekommunikation und Akustik als Leiter der Bell-Gruppe im Jahre 1969 vorlegte.

Erst Mitte der 1980er Jahre erfuhr die Forschung durch die Entdeckung der Differenzierbarkeit von Homophonen mittels Kontextprüfungen neuen Schwung. Indem man Statistiken über die Häufigkeit bestimmter Wortkombinationen erstellte und systematisch auswertete, konnte man bei ähnlich klingenden Wörtern automatisiert herleiten, welches gemeint war.
Ein wichtiger Meilenstein war hierbei die Vorstellung eines neuen Spracherkennungssystems durch IBM im Jahr 1984, das mithilfe von sogenannten „Trigrammstatistiken“ in der Lage war, 5.000 englische Einzelwörter zu verstehen und in Text umzuwandeln. Allerdings verlangte der Erkennungsvorgang damals eine Verarbeitungszeit von mehreren Minuten auf einem industriellen Großrechner und war somit praktisch nicht einsetzbar. Deutlich fortschrittlicher war dagegen ein nur wenig später von Dragon Systems entwickeltes System, das sich auf einem tragbaren PC verwenden ließ.
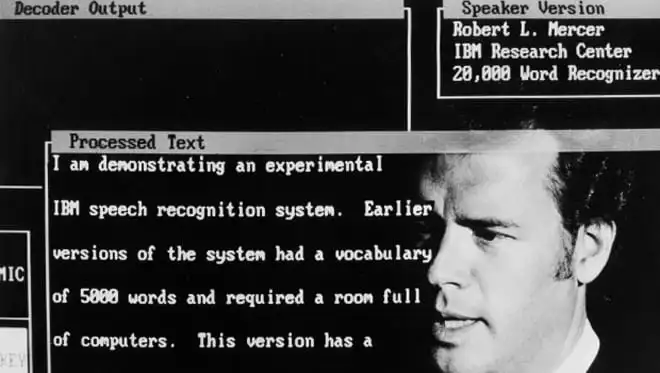
In den folgenden Jahren arbeitete IBM intensiv an der Verbesserung seiner Spracherkennungssoftware. So wurde 1993 das erste für den Massenmarkt entwickelte und kommerziell erwerbliche Spracherkennungssystem, das IBM Personal Dictation System, vorgestellt.
1997 erschienen sowohl die Nachfolgeversion IBM ViaVoice als auch die Version 1.0 der Software Dragon NaturallySpeaking. Während die Weiterentwicklung von IBM ViaVoice nach einigen Jahren eingestellt wurde, entwickelte sich Dragon NaturallySpeaking zur meistverbreiteten Spracherkennungssoftware für Windows-PCs. Seit 2005 wird die Software von Nuance Communications hergestellt und vertrieben.
2008 erlangte Nuance mit dem Erwerb der Philips Speech Recognition Systems auch die Rechte an dem Software Development Kit SpeechMagic, dessen Einsatz insbesondere im Gesundheitswesen verbreitet ist.
2007 wurde die Firma Siri Inc. gegründet und im April 2010 von Apple aufgekauft. Mit der Einführung des iPhone 4s im Jahr 2011 wurde der automatische Sprachassistent Siri erstmals öffentlich vorgestellt und seitdem kontinuierlich weiterentwickelt. Vorstellung von Siri:
Die Funktionsweise hinter den Speech-to-Text Systemen
Moderne Spracherkennungssysteme sind aus unserem Alltag kaum mehr wegzudenken. Doch wie funktionieren sie eigentlich?
Das Grundprinzip der Transkription ist denkbar einfach: Beim Sprechen atmen wir Luft durch die Lunge aus. Je nach Zusammensetzung der gesprochenen Silben versetzen wir die Luft damit in bestimmte Schwingungsmuster, die von der Spracherkennungssoftware erkannt und in eine Klangdatei umgewandelt werden. Diese wird anschließend in kleine Teile unterteilt und gezielt nach bekannten Lauten durchsucht. Weil jedoch längst nicht alle Laute erkannt werden, ist ein Zwischenschritt notwendig.
Mit der sogenannten „Hidden Markov-Methode“ rechnet die Spracherkennungssoftware aus, welcher Laut einem anderen wahrscheinlich folgt und welcher wiederum danach kommen könnte. Auf diese Art entsteht eine Liste möglicher Wörter, mit denen in einem zweiten Durchlauf das passiert, was vorher mit den Buchstaben geschah: Der Rechner analysiert die Wahrscheinlichkeit, mit der ein bestimmtes Wort einem anderen folgt – nach „Ich gehe nach…“ kommt eher „Hause“ als „Brause“ oder „Pause“. Das aber kann der Computer nur wissen, wenn er sehr viele gesprochene Sätze kennt und weiß, wie oft und in welchem Zusammenhang die Wörter vorkommen.
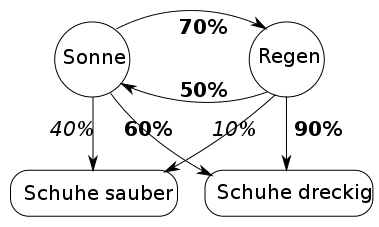
Eine solche Rechenaufgabe übersteigt die Prozessorfähigkeiten eines hosentaschenkleinen Handys um ein Vielfaches. Lösbar ist sie nur durch den Einsatz von Cloud-Computing, also das Auslagern schwieriger Rechenoperationen an stationäre Großcomputer. Das Handy selbst nimmt also lediglich den Sprachbefehl auf, wandelt ihn in eine Tondatei um, schickt diese übers Internet an das Rechenzentrum und lässt sie dort analysieren. Anschließend kommt das Ergebnis über das Internet wieder an das Smartphone zurück.
Die riesigen Datenbanken bereits gesprochener und durch Menschen korrekt transkribierter Sprach- und Textdateien, die per Cloud-Computing vorgehalten werden, sind das eigentliche Geheimnis hinter dem Erfolg der neuen Spracherkenner. Eine gute Spracherkennungssoftware lässt sich also nicht einfach so programmieren, wie ein neues Computerspiel oder ein Druckertreiber. „Die Kunst ist, an gute Daten zu kommen und sie optimal in den Lernprozess einzubauen“ – so Joachim Stegmann, Leiter der Abteilung Future Telecommunication in den Telekom Innovation Laboratories.
Für eine wirklich gute und exakte Spracherkennungssoftware sind zudem besonders viele Aufzeichnungen von Alltagssprache notwendig, so dass auch Dialekte, Sprachfehler, Nuschel- und Fistelstimmen erfasst werden können. Auch demografisch sollten sich die Sprecher unterscheiden – es sollten gleichermaßen viele Kinder, Männer, Frauen, alte und junge Menschen sowie Menschen unterschiedlicher regionaler Herkunft darunter sein. Praktisch werden zum Beispiel Protokolle von Bundestagsreden, vorgelesene Manuskripte oder Aufzeichnungen von Radiosendungen verwendet.
Chancen und Herausforderungen in der Entwicklung automatischer Spracherkennung
Gut funktionierende Spracherkennungssysteme versprechen, unseren Alltag um ein Vielfaches zu erleichtern. In professionellen Einsatzgebieten könnten sie zukünftig besonders die Transkription gesprochener Sprache automatisieren – so zum Beispiel die Aufnahme von Protokollen oder die oft mühevolle manuelle Transkription von Reden, Interviews oder Videos. Auch im privaten Umfeld finden sie immer mehr Verbreitung, sei es zur sprachgesteuerten Bedienung des Smartphones im Auto, dem Aufrufen von Google-Suchen oder der Bedienung von Smart Home-Anwendungen wie dem An- und Ausschalten des Lichts oder dem Herunterregeln der Heizung.
Die große Herausforderung bei der elektronischen Spracherkennung ist jedoch, dass niemand einen Begriff in jeder Situation immer ganz genau gleich ausspricht. Mal ist der Nutzer müde, mal hektisch, mal laut, mal leise, mal konzentriert, mal betrunken, mal sauer, mal erkältet. Deshalb ist es für eine Software sehr schwierig, Wörter durch Suchen deckungsgleicher Tonfolgen zu erkennen.
Besonders ältere Menschen oder Personen in Bewegung sind für die Systeme schwer zu verstehen. Hintergrundgeräusche erschweren die Erkennung noch zusätzlich – Microsoft arbeitet daher bereits an der neuen Software „CRIS“, die eine individuelle Konfiguration häufig auftretender Hintergrundgeräusche und Vokabeln ermöglichen und somit auch einen Einsatz in lauten Produktionsbereichen oder in Seniorenheimen zulassen soll.
Zwischenzeitlich erreichen aktuelle Systeme beim Diktat von Fließtexten auf Personal Computern Erkennungsquoten von ca. 99 Prozent und erfüllen damit für viele Einsatzgebiete die Anforderungen der Praxis, z. B. für wissenschaftliche Texte, Geschäftskorrespondenz oder juristische Schriftsätze. An Grenzen stößt der Einsatz dort, wo der jeweilige Autor ständig neue, von der Software zunächst nicht erkennbare Wörter und Wortformen benötigt, deren manuelle Hinzufügung zwar möglich, aber bei nur einmaligem Vorkommen in Texten desselben Sprechers einfach nicht effizient ist.
Die bedeutendsten Anbieter automatischer Spracherkennungssysteme
Wie bei vielen modernen Technologien schießen neue Anbieter auf dem Gebiet der Audio-Transkription wie Pilze aus dem Boden.
Marktführer in der automatischen Spracherkennung und Transkription ist Nuance mit seiner Dragon NaturallySpeaking-Software. Der Einsatz der Deep Learning-Technik ermöglicht den Einsatz der Software auch in Umgebungen mit starken Hintergrundgeräuschen. Durch ein gezieltes Training auf einen spezifischen Sprecher lässt sich mit nur wenigen Minuten investierter „Vorlesezeit“ eine Genauigkeit von bis zu 99% in der Speech-to-Text-Umwandlung erreichen. Bei Nuance arbeitet man derweil an der nächsten Generation der Auto-Elektronik, die zukünftig das exakte Schreiben komplizierter Texte per Spracheingabe, die Nutzung sozialer Netzwerke und die Befragung von Suchmaschinen ermöglichen soll, ohne die Aufmerksamkeit des Fahrers dabei von der Fahrbahn abzulenken.
Die gleiche Technolige nutzend, jedoch weitaus bekannter als Nuance ist jedoch wahrscheinlich Siri, der persönliche Sprachassistent, der Apple-Nutzern seit dem Release des iPhone 4s zur Verfügung steht. Die Software lässt sich mit dem Befehl „Hey Siri“ starten und verlangt somit fast überhaupt keine manuelle Bedienung mehr. Als Spracherkennungssoftware zum Diktieren ganzer Briefe oder längerer Texte ist es jedoch nur eingeschränkt geeignet, da nicht kontinuierlich Sprache aufgenommen und fortlaufend digitaler Text ausgegeben wird. Siri speichert einige gesprochene Sätze, bis diese mit einem „Fertig“-Befehl zum zentralen Übersetzungsserver gesendet werden oder bricht die Textaufnahme für die Übertragung ab, wenn der maximale Speicher erreicht ist. Bis der digitale Text rückübermittelt worden ist, muss das Diktat pausieren. Diese Übermittlung birgt Risiken für die Informationssicherheit, des Weiteren geht bei einer Unterbrechung der Übertragung, z.B. in einem GSM Funkloch, der diktierte Text verloren.
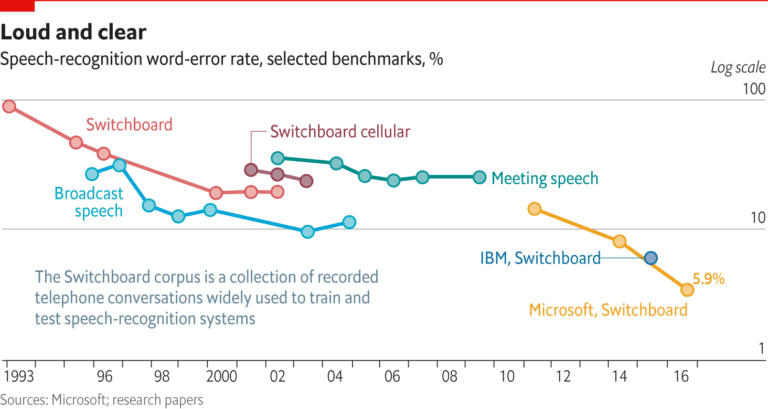
Vergleichbar zu Apples Siri betreibt Microsoft auf seinem Windows Phone 8.1. den virtuellen Assistenten Cortana, der sich der Bing!-Suche sowie auf dem Smartphone gespeicherter persönlicher Informationen bedient, um dem Benutzer personalisierte Empfehlungen zu liefern. Eine Ausweitung der Funktionen auf die smarte Steuerung von Haushaltsgeräten wie Kühlschränken, Toastern oder Thermostaten durch die Technologie des Internet der Dinge ist bereits geplant. Mit seiner Spracherkennungssoftware, dem sogenannten „Computational Network Toolkit“ konnte Microsoft zudem im Oktober 2016 einen historischen Meilenstein setzen: Mithilfe der Deep Learning-Technologie konnte die Software in Vergleichstests zwischen Mensch und Maschine eine Fehlerrate von nur 5,9% erzielen – dieselbe Fehlerrate wie ihre menschlichen Counterparts. Die Software hat damit die Gleichstellung zwischen Mensch und Maschine erstmals erreicht.
Auch Google hat im März 2016 eine Programmierschnittstelle für Cloud-Dienste als Beta-Version geöffnet. Die Cloud Speech API übersetzt gesprochenen in geschriebenen Text und erkennt rund 80 Sprachen und Sprachvarianten. Die API kann den Text bereits während des Erkennens als Stream ausliefern und filtert Hintergrundgeräusche selbsttätig heraus. Sie steht derzeit nur Entwicklern zur Verfügung.
Zuletzt hat auch Amazon den Release des neuen Service „Amazon Lex“ für die Entwicklung von Konversationsoberflächen mit Stimme und Text angekündigt. Er basiert auf der Technologie für automatische Spracherkennung und natürliches Sprachverständnis, die auch Amazon Alexa nutzt. Entwickler können mit dem neuen Service zukünftig intelligente Sprachassistenten – sogenannte Bots – bauen und testen.
Und das Kognitive System IBM Watson, das 2011 den Aufbruch in die Ära des Cognitive Computing markierte, macht sich neben neuronalen Netzwerken, Machine Learning und Textanalyse-Tools insbesondere die Spracherkennung zunutze, um selbst zu lernen. Inzwischen stellen für IBM Watson selbst Ironie, Metaphern und Wortspiele kein Hindernis mehr dar.
Fazit
In den letzten Jahren hat sich die Technologie, insbesondere gestützt durch Cloud Computing und die dadurch mögliche automatisierte Verarbeitung extrem großer Datenmengen als Basis für intelligente Systeme, rasant weiterentwickelt. Mithilfe professioneller Spracherkennungssoftware ist die automatische Transkription schon heute nahezu fehlerfrei möglich.
Reine Spracherkennungssysteme an sich sind aber erst der Anfang. Wahrhafte Interaktion zwischen Mensch und Maschine – so, wie es die Science-Fiction-Filme prophezeien – verlangen Maschinen, die Informationen nicht nur wiedergeben, sondern Sinnzusammenhänge verstehen und intelligente Entscheidungen treffen können.
Weitere Fragen und Antworten
 Wie funktioniert Spracherkennung?
Wie funktioniert Spracherkennung?
Die Systeme zur automatischen Spracherkennung funktionieren grundsätzlich alle gleich.
Einfach gesprochen ist der Kern immer eine große Datenbank, in der viele mögliche Varianten der Aussprache von einem oder mehrerer Wörter mit dem passenden Text gespeichert sind. Wenn dann eine neue Aufnahme in das System eingespielt wird, dann vergleicht dieses den Ton mit der Datenbank und gibt den Text aus, der am wahrscheinlichsten dieser Aufnahme entspricht.
Je größer und besser gepflegt diese Datenbank ist, desto besser ist dann auch die Spracherkennung. Des weiteren spielt natürlich die Aufnahmequalität eine große Rolle, um eine gute Erkennungsrate zu erreichen.
Kann man mit einer Spracherkennung transkribieren?
Die Transkription mit einer Spracherkennung ist möglich.
Bein einem Diktat von einer Person mit klarer Aussprache, ohne Dialekt und ohne Störgeräusche kann mit einer Spracherkennung ein Qualitätsniveau von ca. 90% erreicht werden. Dies ist nur noch knapp unter dem üblichen menschlichen Transkriptionsniveau von ca. 95%. Fehlt eine dieser Voraussetzungen und bei nahezu allen Interviews oder Gruppengesprächen sind heutige Systeme zur Spracherkennung noch nicht in der Lage, verständliche Texte zu generieren.
Nach aktuellen wissenschaftlichen Studien erreicht die Spracherkennung bei Interviews aktuell ein Niveau von nur etwa 65%, was zu größtenteils unverständlichen Texten führt.

abtipper.de ist Marktführer für die Verschriftlichung von Audio- & Videodateien. Unsere Vorteile:
- Preise ab 1,65 €/Minute
- Qualifizierte Fachkräfte
- Absolute Vertraulichkeit
- Top-Referenzen:

Fragen Sie
ein unverbindliches Angebot an